GT300 architecture in detail
![]()
|
xtreview is your : Video card - cpu - memory - Hard drive - power supply unit source |
|
|||
|
|
||||

 Recommended : Free unlimited image hosting with image editor
Recommended : Free unlimited image hosting with image editor
|
POSTER: computer news || GT300 ARCHITECTURE IN DETAIL |
DATE:2009-10-02 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Besides the photographs of graphic accelerator NVIDIA tesla, during the official announcement of graphic processor GT300 was shown new information concerning the architecture with the code name fermi. On the slides are demonstrated the general characteristics of this card, the organization of stream multiprocessors and their structure, results of productivity in floating-point calculations and other.
The graphic processor new generation GT300 contains three billion transistors, it has 512 shader core and ensures productivity in the calculations with double precision, eight times exceeding productivity GT200 chip .  Stream multiprocessors are located around the general cache of the second level. On the slide, each multiprocessor is the vertical rectangle, which contains the orange part (planner and organizer), the green part (executive modules) and the blue parts ( registers files and first level cache ). 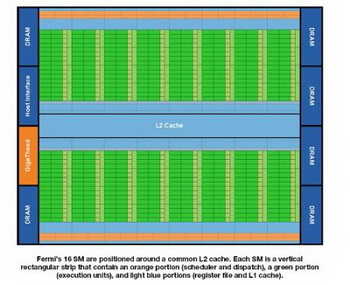 On the following slide, the internal structure of multiprocessor is shown. Each of 16 multiprocessors has 32 shader core.  Concerning memory, new GPU has six 64-bit GDDR5 memory controllers , this gives the 384- bit memory bus and support up to 6 GB GDDR5 memory. Fermi is the first architecture, which supports the errors correction code (ECC) for data, which are stored in the memory. The technology NVIDIA parallel dataCache considerably accelerates mathematical calculations and fulfillment of other functions. On the slide is shown the comparison of productivity in the calculations of floating-point numbers with double precision between tesla c1060 and new model on fermi architecture . In the test with 20480 objects the novelty shows the result of 18,16 frames per second, producing in a second 7,61 billion iterations. Its predecessor is capable only to 3,52 sequences per second, 1,47 billion iterations per second.  The solutions on fermi architecture are called first in the world computational GPU. Because the collection of parallel thread instruction eXecution second generation (PTX 2.0), in them is realized the hardware support of programming as C, C++, Fortran and other function sets (such as the standardized address space, OpenCL and DirectCompute). The basic task Of fermi is considered the transfer of calculations on the large data array to GPU.  It is expected that in the next months NVIDIA company will finish the work on GT300 chip. In conclusion, we give the comparative table of GT300 chip characteristics and its predecessors:
Related Products : | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
xtreview is your : Video card - cpu - memory - Hard drive - power supply unit source |
|
|
|
|
||
|
Xtreview Support  N-Post:xxxx Xtreview Support  |
GT300 ARCHITECTURE IN DETAIL |
| Please Feel Free to write any Comment; Thanks  |
AMD processors with Zen architecture of the second generation will raise frequencies and specific performance (2017-09-05)
AMD Navi graphics architecture will open in the corporate segment (2017-07-24)
In the new architecture of processors, Intel abandoned the internal ring bus (2017-06-16)
The most productive representative of Vega architecture will be released in the second half of 2018 (2017-05-29)
The development of Zen 3 architecture AMD experts have already begun (2017-05-19)
Open architecture of RISC-V can now be purchased online (2017-05-06)
AMD Zen architecture has no place in Microsoft Project Scorpio (2017-04-19)
Architecture AMD Vega will leave its mark in the game console Microsoft Project Scorpio (2017-04-17)
In Japan, single-slot Quadro graphics accelerators with Pascal architecture appeared on sale (2017-04-06)
Microsoft is testing server solutions based on processors with ARM architecture (2017-03-09)
Processors with x86-based architecture and smartphones Intel business is alive and well (2017-02-28)
Intel is looking for talents for the development of a revolutionary processor architecture (2017-01-24)
In the next four years, AMD Zen architecture will evolve (2017-01-06)
AMD graphics cards promises intrigue fans with a new architecture (2016-12-28)
By the end of the decade, Intel give birth to fundamentally new architecture (2016-12-26)
Alibaba may move their servers to use processors with ARM architecture (2016-12-13)
Create products with ARM architecture is not a priority for AMD investments (2016-12-10)
Samples of Zen architecture processors come from a mid-year (2016-12-09)
AMD is preparing at least two more GPUs Polaris architecture (2016-12-08)
AMD says about the place of ARM architecture in its strategy (2016-12-01)
![]()

To figure out your best laptops .Welcome to XTreview.com. Here u can find a complete computer hardware guide and laptop rating .More than 500 reviews of modern PC to understand the basic architecture


7600gt review
7600gt is the middle card range.
We already benchmarked this video card and found that ...
 geforce 8800gtx and 8800gts Xtreview software download Section AMD TURION 64 X2 REVIEW INTEL PENTIUM D 920 , INTEL PENTIUM D 930 6800XT REVIEW computer hardware REVIEW INTEL CONROE CORE DUO 2 REVIEW VS AMD AM2 INTEL PENTIUM D 805 INTEL D805 Free desktop wallpaper online fighting game Xtreview price comparison center
geforce 8800gtx and 8800gts Xtreview software download Section AMD TURION 64 X2 REVIEW INTEL PENTIUM D 920 , INTEL PENTIUM D 930 6800XT REVIEW computer hardware REVIEW INTEL CONROE CORE DUO 2 REVIEW VS AMD AM2 INTEL PENTIUM D 805 INTEL D805 Free desktop wallpaper online fighting game Xtreview price comparison center 
Rss Feeds

- The new version of GPU-Z finally kills the belief in the miracle of Vega transformation
- The motherboard manufacturer confirms the characteristics of the processors Coffee Lake
- We are looking for copper coolers on NVIDIA Volta computing accelerators
- Unofficially about Intels plans to release 300-series chipset
- The Japanese representation of AMD offered monetary compensation to the first buyers of Ryzen Threadripper
- This year will not be released more than 45 million motherboards
- TSMC denies the presentation of charges from the antimonopoly authorities
- Radeon RX Vega 64 at frequencies 1802-1000 MHz updated the record GPUPI 1B
- AMD itself would like to believe that mobile processors Ryzen have already been released
- AMD Vega 20 will find application in accelerating computations
- Pre-orders for new iPhone start next week
- Radeon RX Vega 57, 58 and 59: the wonders of transformation
- ASML starts commercial delivery of EUV-scanners
- The older Skylake processors with a free multiplier are removed from production
- Meizu will release Android-smartphone based on Helio P40
- AMD Bristol Ridge processors are also available in American retail
- The fate of Toshiba Memory can be solved to the next environment
- duo GeForce GTX 1080 Ti in GPUPI 1B at frequencies of 2480-10320 MHz
- New Kentsfield overclocking record up to 5204 MHz
- Lenovo released Android-smartphone K8



computer news computer parts review Old Forum Downloads New Forum Login Join Articles terms Hardware blog Sitemap Get Freebies